Research Overview
The paradigm shift towards the Internet of Things (IoT), edge computing, and the rise of mobile applications in various domains has necessitated the development and deployment of efficient AI models on devices. This is a significant shift from the traditional cloud-centric model, where computationally heavy models run on powerful remote servers. There are numerous challenges associated with implementing on-device AI, notably the constrained computational, memory, and energy resources, coupled with the demand for real-time processing and data privacy. Our research aims to address these challenges by focusing on improving the efficiency of foundation AI models and their application on-device, through the integration of algorithm and system co-design.
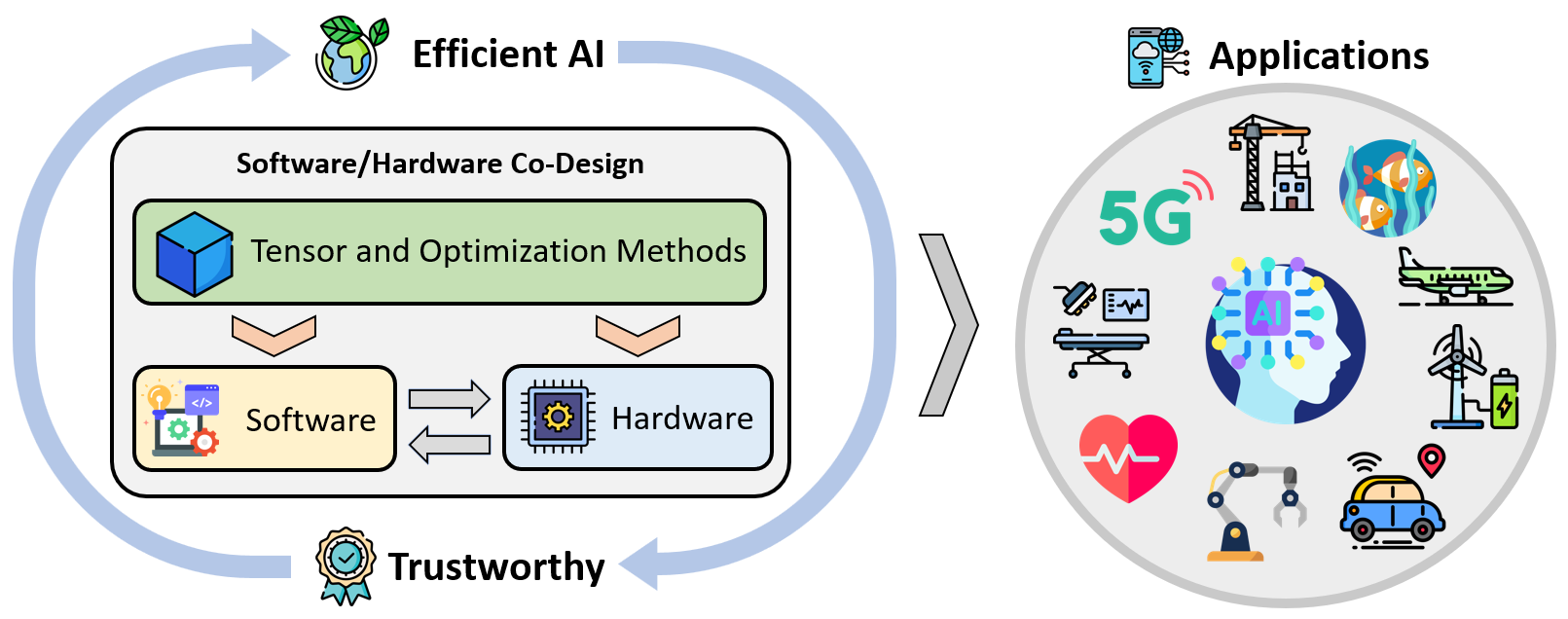
Our primary objective is to conduct rigorous research and development focusing on integrating algorithm and system co-design principles in the AI ecosystem. The aim is to create trustworthy, efficient, and adaptable AI models that can operate effectively within the limited resources of on-device platforms, then democratizing AI to real-world on-device applications. Our research draws upon methodologies from mathematical tools, machine learning, computer architecture, and high-performance computing. We specifically build the general framework of algorithm/system co-design for efficient and trustworthy AI based on higher-order tensor decomposition and optimization algorithms, then apply the corresponding AI models to on-device applications.
Here are some themes and techniques that we work on:
AI Model Optimization with Higher-Order Tensor Decomposition. At the heart of the research lies the concept of tensor decomposition, a high-dimensional analogue of matrix factorization. Given that DL models’ parameters inherently form high-dimensional arrays (tensors), we propose exploiting this structure for efficient compression. 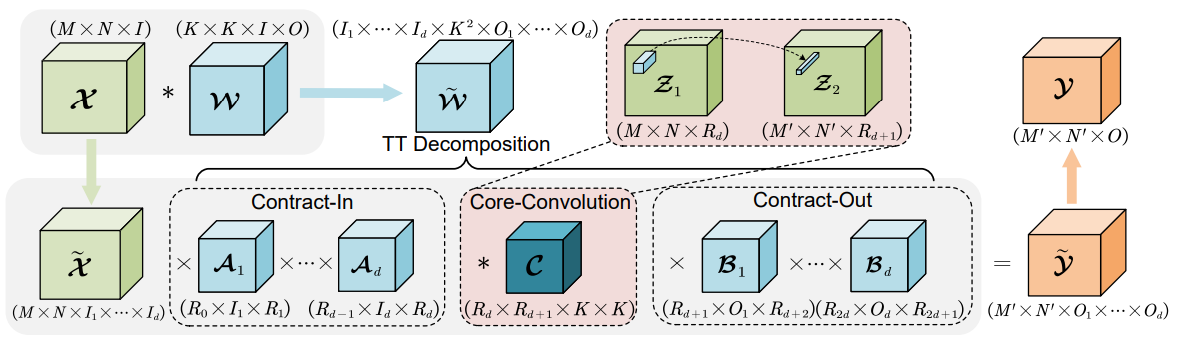 Tensor decomposition allows us to break down large weight tensors into a series of smaller tensors, significantly reducing storage requirements and computational load without drastically impacting the model’s predictive performance.
The research encompasses a detailed investigation of various tensor decomposition techniques, including CANDECOMP/PARAFAC (CP), Tucker, and Tensor Train (TT) decompositions, and their application to the weights of convolutional layers in DL models. We propose a systematic methodology, starting from decomposing the original tensors to retraining the compressed model to recover potential performance loss. The study also includes an in-depth examination of the trade-off between the degree of compression and the preserved accuracy.
Tensor decomposition allows us to break down large weight tensors into a series of smaller tensors, significantly reducing storage requirements and computational load without drastically impacting the model’s predictive performance.
The research encompasses a detailed investigation of various tensor decomposition techniques, including CANDECOMP/PARAFAC (CP), Tucker, and Tensor Train (TT) decompositions, and their application to the weights of convolutional layers in DL models. We propose a systematic methodology, starting from decomposing the original tensors to retraining the compressed model to recover potential performance loss. The study also includes an in-depth examination of the trade-off between the degree of compression and the preserved accuracy.
Hardware-Aware Model Acceleration. Our research involves developing efficient parallel algorithms for various optimized AI models based on tensor decomposition, tailored for execution on GPU architectures. 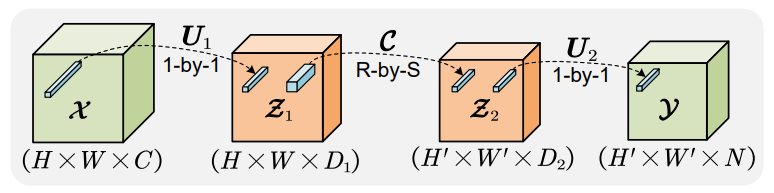 These algorithms break down the complex tensor decomposition tasks into simpler sub-tasks that can be performed concurrently, thus significantly accelerating the final compressed tensor format models. Our study also improves the scalability of these parallel algorithms concerning tensor dimensions and the GPU’s hardware specifications.
These algorithms break down the complex tensor decomposition tasks into simpler sub-tasks that can be performed concurrently, thus significantly accelerating the final compressed tensor format models. Our study also improves the scalability of these parallel algorithms concerning tensor dimensions and the GPU’s hardware specifications.
Software-Hardware Co-Design. To foster true synergy between AI software and hardware, we develop a co-design framework that simultaneously considers model optimization and hardware constraints. 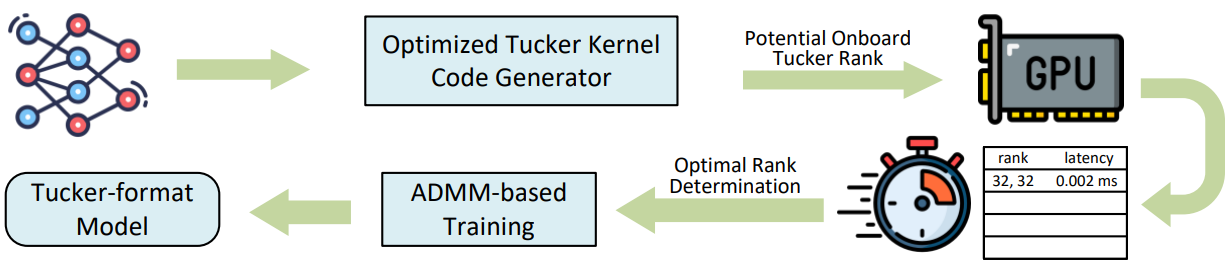 This holistic approach will ensure a balance between AI model efficiency and hardware capabilities. In addition to generate highly accurate and compact tensor format DNN models with optimized C++/CUDA code, which can be easily deployed on GPUs for high-performance inference, we also aim to automate the entire efficient software and hardware co-optimization process by determining the proper Tucker ranks based on a target speedup of inference performance.
This holistic approach will ensure a balance between AI model efficiency and hardware capabilities. In addition to generate highly accurate and compact tensor format DNN models with optimized C++/CUDA code, which can be easily deployed on GPUs for high-performance inference, we also aim to automate the entire efficient software and hardware co-optimization process by determining the proper Tucker ranks based on a target speedup of inference performance.